
 摘要:
...
摘要:
... 
本文为澎湃号·湃客科技 × 光锥智能 联合出品,湃客科技栏目独家首发,未经允许禁止转发
文|魏琳华
编|王一粟
“人已经多到炸馆,逛展堪比庙会。”
2025年,WAIC的火爆程度已经不用多说:闲鱼上炒到2000元一张的门票;现场随处可见的老外;各个展区被人流挤得水泄不通......
光是外围的火爆就已经说明——今年,AI大模型在应用上已经势如破竹。
前所未有的参展产品数量,是AI应用遍地开花的佐证:创纪录的800家企业参展,带来3000余产品及100+首发新品参展,涵盖40+大模型、50+AI终端产品、60+智能机器人,和去年相比,产品数量整整翻了一番,不少观众散会纷纷戏称“逛到断腿”。
在一个展区中,你能看到各个品类下不同厂商演绎的多种玩法:机器人1:1复刻人类动作、给人类调酒、搬东西;Agent写代码、作文、当理财助手;AI+教育不仅有AI学习机、还搬上了AI黑板......
比起看得见摸不着的Agent“数字员工”,能看到实体的智能机器人成为了会场的“顶流”。
H3展馆中,大片机器人“整活”的场景相当壮观:和真人对打的宇树机器人、练习摞百事可乐的智元机器人、魔法原子的机器狗绕着场馆跑来跑去......
除了面向C端用户的产品爆发,在B端,AI也已经在企业中应用起来。
“就在我们公司内部,员工每天需要写很多代码,做很多研究型实验,这里边大概有 70% 的代码是 AI 来写,90% 数据分析是靠 AI 来做。”在MiniMax CEO闫俊杰的分享中,Agent构建的智能系统已经真正帮上了员工的忙。
随着年初大模型进入深度推理阶段,性能进入高可用的程度,加上训练和推理成本进一步降低。经过三年的一路狂奔,厂商们终于高调地秀起了肌肉。

推理模型的“爆发年”
从模仿学习到强化学习,大模型已经进化到2.0时代。
以OpenAI的o1模型为分水岭,2025年成了推理模型的“爆发年”。区别于以往靠大量监督数据提升性能,通过RL(强化学习)算法的训练模式,让大模型的能力迈上新一个阶段。
由此,文字、视觉、多模态等领域,叠加推理能力成了国内大模型公司上半年角逐的重点。
在WAIC大会上,“大模型新五强”之一阶跃星辰就在会上发布了自家原生多模态推理模型Step-3,在开源梯队中达到SOTA;商汤同样在论坛中发布日日新V6.5多模态基座大模型,强调强推理、高效率和智能体三大优化。
大方向转向强化学习的基础上,一个明显的趋势是,训练和推理的成本在上半年进一步降低。通过使用新模型架构的优化、训练算法的进步以及软硬件协同的算力效率提升,大模型们开始比肩DeepSeek,给出更便宜的训练和推理成本。
闫俊杰给出了一个更为乐观的判断,认为在接下来一两年之内,最好模型的推理成本可能还能再降低一个数量级。
再从应用方向来看,出于商业化落地考虑,绝大部分模型不会再去做上万的参数,同时向着商业化路线的应用要求考虑。
以视频生成来说,生数科技CEO骆怡航认为,目前整个视频生成还有进一步优化空间,他总结为“好快省”。
“首先一致性还需要提升,然后在生成的速度上还需要加快,第三是,在视频生成的成本上还要大幅降低。”骆怡航说。
对应到落地产品上,几家视频模型产品不约而同地贴合专业赛道的制作方向做优化。生数科技旗下的产品Vidu 7月发布的Vidu Q1 参考生视频功能,改变传统视频制作流程和AI图生视频流程,仅需上传人物、道具、场景等参考图,即可直接生成一段视频,完全省去了分镜制作的环节,并且参考生支持7个主体一致不变形;快手可灵AI则在会议期间发布“灵动画布”,把AI辅助和多人协作放到了一块无限大的工作界面中。
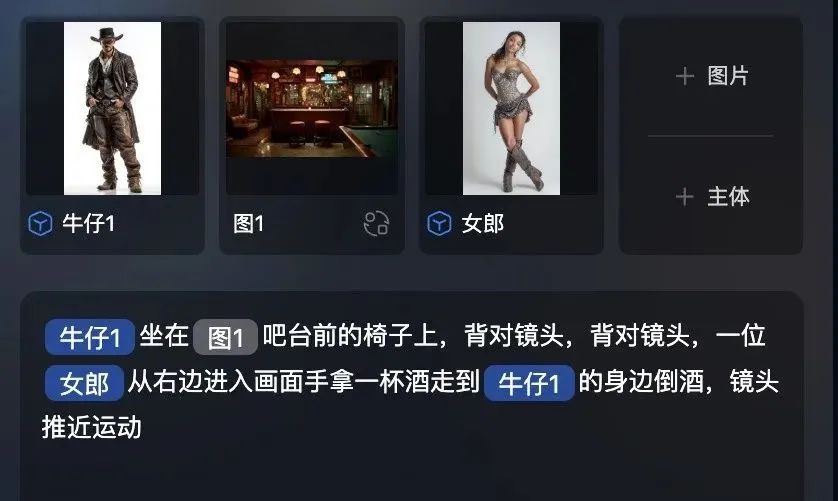

Vidu Q1 参考生视频
另外,AI公司们也开始围绕着两个业内更加关注的产品落地——Agent和具身智能,为其打造专属能力匹配的模型。
从智能体的发展来看,今年上半年涌现出一些为Agent“量身定做”的模型,比如更匹配上下文理解的超长文本模型、优化Agent“视力”的视觉推理模型。再有,随着具身智能的火爆,为机器人打磨“视觉”和“大脑”的任务也落在了大模型公司们的身上。在商汤、科大讯飞、阶跃星辰等公司的展台,也有机器人在站台表演。

最火热的落地:Agent、具身智能
当大模型能力突破到一定阶段,应用也随之爆发。
阶跃星辰创始人、CEO姜大昕表示:“从Step 1到Step 2两代基模的快速迭代,促使我们深入思考什么才是最适合应用的模型。随着大模型进入到强化学习发展阶段,新一代推理模型成为主流,模型性能的提升固然显著,但这是否完全等同于模型价值?面对这一产业之问,我们必须回归客户需求,立足真实应用场景,探索模型创新落地的可行路径。
在WAIC现场,Agent和具身智能成了会场中最热门的两个赛道。多模态能力和推理能力的提升,让Agent和具身智能装上了“眼睛”和“大脑”。
Agent,几乎出现在各个展台中:
面向C端用户,有少量通用Agent和多种面向细分场景的垂类Agent。比如智谱的Agent助手Coco专注AI写作,阶跃星辰的Agent则装到了智能手机端上,搭载AI拍照问、AI助手等功能;刚上新全栈功能的MiniMax Agent,能让用户在几分钟做个网页出来。

在智能硬件端,Agent也开始接管起人的生活体验。美的高端定位AI科技家电品牌COLMO落地应用了行业首个适配家电家居全场景的AI agent智能体——COLMO AI管家,通过“多维感知-自主学习-推理规划-决策执行”,提升智能家居对场景的理解能力。

做To B生意的软硬件厂商,智能体成为企业帮助客户增量提效的落地手段。除了在软件端应用,软硬件协同的厂商也在AI平台中植入智能体服务。在DeepSeek一体机展台,光锥智能就见到了政务/医疗等领域的Agent,作为其软件服务端的新产品能力。
在上半年的进展中,一个明显的趋势是,AI Agent从打辅助的定位,已经开始过渡到自主驱动任务完成的阶段。
以亚马逊云科技发布的编程智能体Kiro为例,它的Spider模式,在Agent执行任务的需求-计划-执行过程中,AI已经能在每个环节中提供助力。Kiro技术专家举了个例子,比如,当用户给出一句话需求后,AI会根据需求创建更为详细的PrD(产品需求文档),把各种隐性的需求挖掘出来,确保AI能够精准执行任务,做出可交付的产品。
在企业内部,多智能体的运转协作已经初见成效。
谈及大模型在工厂内部的落地,美的集团副总裁兼CDO张小懿告诉光锥智能,目前已经看到了工厂用大模型的能力在进行工厂的运营改进,在3-4个月的尝试中,目前靠智能体已经能帮助产品实现品质和效率上的提升。
“在美的洗衣机荆州工厂,我们已经上线了14个智能体,这14个智能体能够互相关联起来运行,”张小懿说。过往,这些数据全都需要人和人直接沟通协作,寻找问题根源。但交给智能体后,它自己就会找当时的参数情况、设备、产线和具体型号,再判断出大致的结果。
“把控品质的智能体,它能够把相关数据全部回流到其中,实时判断情况,当发现品质波动,它反过来会影响到负责产品设备维护的智能体和设备工艺智能体。”张小懿说。
纵观下来,Agent市场在半年的搭建过后,在和企业磨合试验的过程中,暴露出一些技术上亟待完善的工作。
有Agent平台工作人员告诉光锥智能,目前开发者们更关注长时记忆和MCP的生态扩充,前者决定了让Agent能够在需要长久记忆的场景保留上下文信息,而针对一些即时场景,则需要及时将信息清理,避免无谓的成本浪费;MCP的扩充让Agent有更多工具可供调用。
同样靠大模型武装“大小脑”的具身智能,成为了这次展会品类数量最多的一个。
以具身智能的头部来说,其主要包含大脑、小脑两个部分。以主流的“大小脑”分层架构来说,其中多模态大模型作为“大脑”,负责感知、理解和规划;再由多个小模型结合运动控制算法组成“小脑”,负责运动控制和动作生成。
不过,对于产品百花齐放、融资热切的具身智能赛道来说,一切还处在开始阶段,距离实际场景来说,还离落地太远。
其中发生在机器人赛道的一个问题是,今年,软硬件拉开的差距更大了。
和云深处合作布局安防机器人赛道,康迪机器人技术总监崔广章对光锥智能表示,目前,硬件与软件之间的代差还在加大。软件已经进入了验证到量产的过程,但硬件还没有达到,在功能、稳定性和成本表现上还差了一些。
目前,面向工业的机器人的软硬件水平,已经可以满足在特定工业场景下的一些任务。康迪科技和云深处合作的机器狗将销向北美,用于北美仓库的安防巡检场景。
犹如去年徘徊的大模型落地,这两条赛道还需要更多的摸索和模型能力的进化支撑。

加速落地
“AI大模型的发展,从人工智能第四次浪潮的元年2022年开始,各路英豪都在一路狂奔。”科大讯飞副总裁李翔说。
在大模型技术上线不断被拓宽的过程中,AI+大模型也在重构产业智能的生态。在B端,通过AI挖掘数据和产业互联网的价值,大模型和智能体逐渐承担起更多提升收入、降低成本的任务。
“市面上的开源大模型很多,但它们都是独立的个体”,做AI+工业互联网的卡奥斯化工行业总经理康健告诉光锥智能,“无论是垂类小模型还是行业模型,散点的价值还是有限的。”
以化工大模型为例,卡奥斯没有选择上来就做模型,而是搭了一个工业互联网平台,把三个城市的所有集团和二级单位的业务和数据拉通,再进行数据收集和治理。在这个基础上,大模型和智能体,就有了业务的需求拉动及数据的支撑。
康健举了个例子,以延长石油为例,生产经营智能体及市场产品价格预测智能体的协同应用,会根据产业链上的实时情况调整生产策略。根据成品油及化工品的价格及收益情况,调整生产计划及各自产能,让集团产业链价值最大化。
“没有业务及数据的互连,它拉通不了全产业链和全价值链,就不能把用户本身和供应商连起来,如果不连起来,智能体的价值就无法最大化。”康健说,“用单场景模型,你一年可能省10万,如果基于我们的全产业链大模型进行智能优化,可能全年的价值是一个亿”。
比起去年清一水但稍显苍白的行业客服、对话助手,通过深度结合行业数据,AI今年在各行各业跑出了一些更具行业针对性的新功能,展现出更为成熟和实用的应用前景。
在AI+医疗行业中,大模型公司通过和医院合作,在数据训练的基础上,一些有应用价值的功能开始陆续落地。阿里在展示台放了一个AI CT扫描的功能,基于其通用多模态医疗大模型,模型能够根据病人的医学影像自动生成详细的诊断报告,辅助医生做判断。
模型的能力决定应用的上限,今年同理。其中一个明显的节点就是推理模型DeepSeek-R1为代表的各个推理模型发布,进一步提升了AI在行业中的应用能力。
以教育行业为例,以DeepSeek为代表的推理大模型能力突破,在AI教育方面找到了对应的应用场景。

“通常来讲,家长对于AI教育有很多顾虑,比如担心直接抄答案、误导学生,但是今年最大的一个利好就是DeepSeek的出现。”学而思学习机AI产品负责人李通说。“只有当家长自己试过大模型,并且认可了能力,他才会愿意让自己的孩子也试一试。”
李通提及,编程和解题是基座大模型过去一段时间提升较为明显的能力。对于纯文本数学题,大模型能在完全没见过的情况下,做到92%的准确率。在解题率提升的基础上,今年AI在大模型一对一讲题这个场景,在过去的这段时间里面出现明显的突破。
从“炫技”到“实干”,AI大模型正破冰行业深水区。随着AI能力的进一步突破,冰山之下蕴藏的价值,才会慢慢展现全貌。




还没有评论,来说两句吧...